


概述
计算机图形学回顾(game101),,但CG更多关注理论,与真实的游戏中的绘制系统还是有区别,在游戏的绘制系统中有四个难点:
需要到达的效果非常复杂:需要处理非常多不同的材质,比如水面、毛发、云彩等等,还需要大量后处理和光照计算
需要深度硬件适配
需要优化帧率与画质
注重游戏优化,除了绘制系统还有给gameplay系统留下内存与CPU空间
游戏引擎中的绘制是一门实践科学,经过行业发展一点点升级,迭代优化非常快速
渲染对象
基础管线:CPU->几何->光栅化
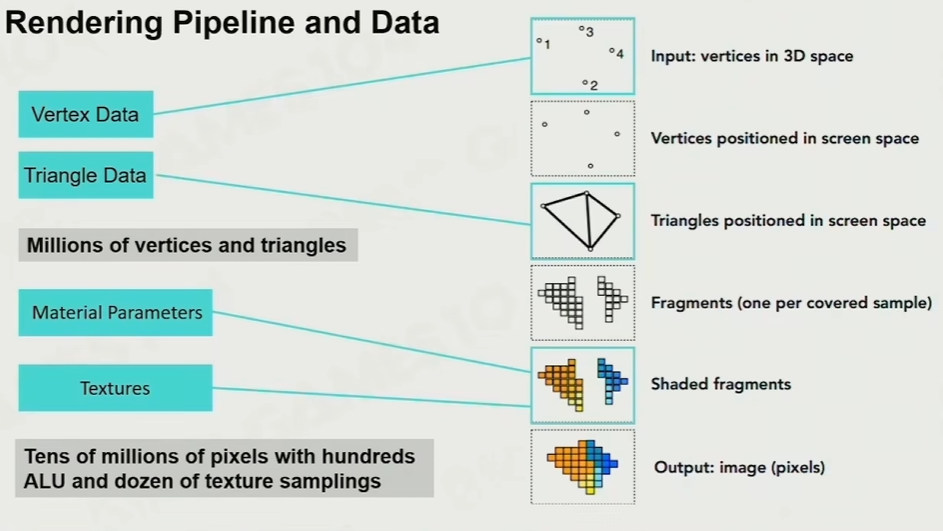
详见课程 game101 计算机图形学入门
投影->光栅化->着色
纹理采样:
为了防止走样,详情可见game101-mipmap,实际是一个非常消耗性能的过程,因为需要多次采样与插值,所以需要通过GPU计算
GPU做了什么
SIMD与SIMT
SIMD(SingleInstructionMultipleData):指令级并行
SIMT(SingleInstructionMultipleThread):单指令多核多线程
本质上可以理解为在多核上做同样的事
GPU架构
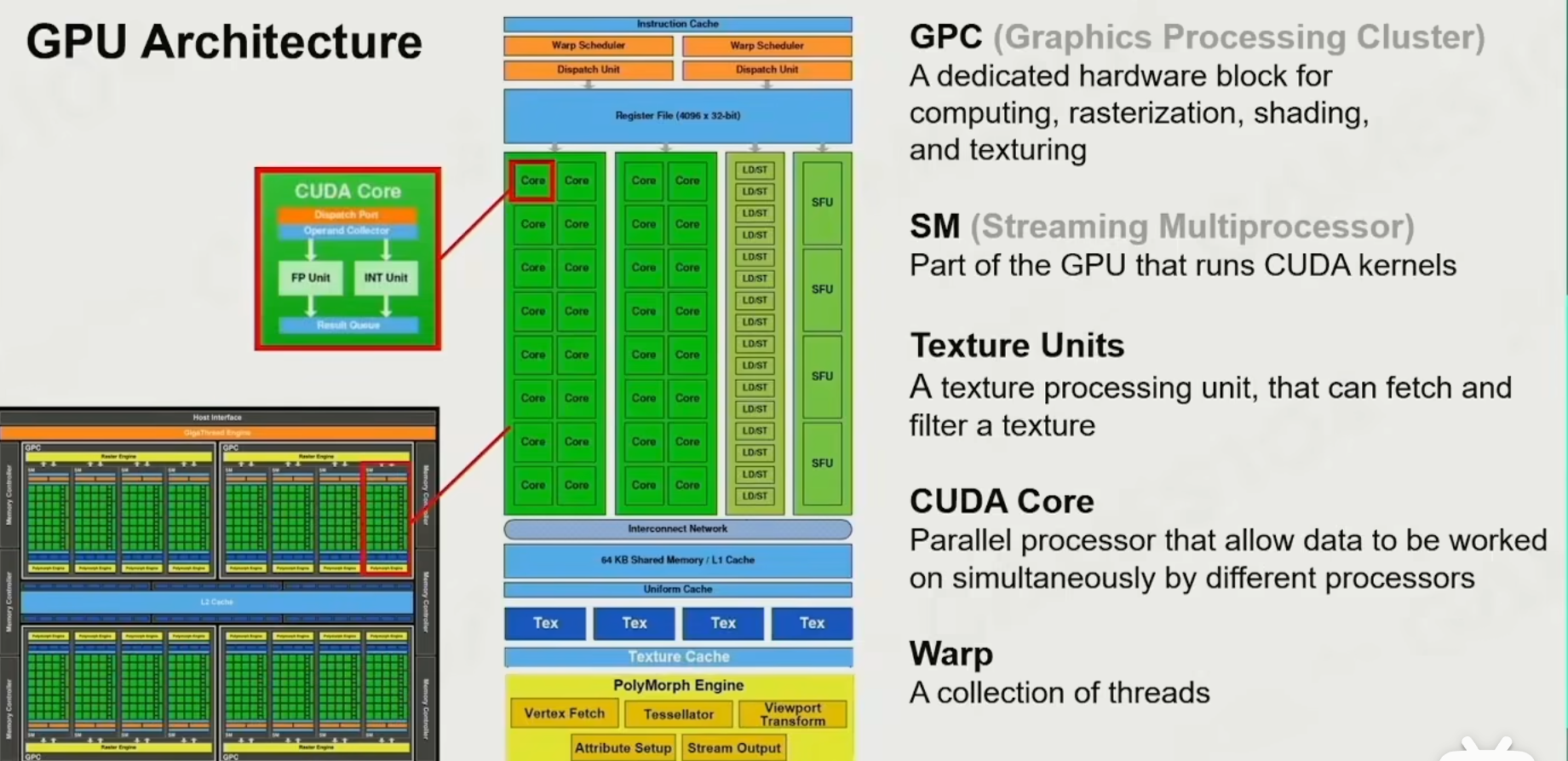
GPC:图形处理集群,即将内核分组,每组成为一个GPC
SM(streamingMultiprocessor):每个GPC中又有许多的SM,即流多处理器,有专门的硬件处理纹理采样(TextureUnits)、计算单元(SFU)、RTCore(光追)等等
从CPU到GPU的数据流
从内存到显存的数据交换速度是非常慢的,(所以需要减少drawCall)
为了避免逻辑与渲染的不同步,需要尽量控制数据为CPU到GPU的单向传输
缓存效率:缓存对性能的影响极大,数据需要集中放置,增加缓存命中率
GPU Bound And Performance
可以理解为各个线程的同步,数据等待
ALU Bound:等待计算结果
TMU(TextureMappingUnit)Bound:等待纹理采样
BW(Bandwidth)Bound、MemoryBound
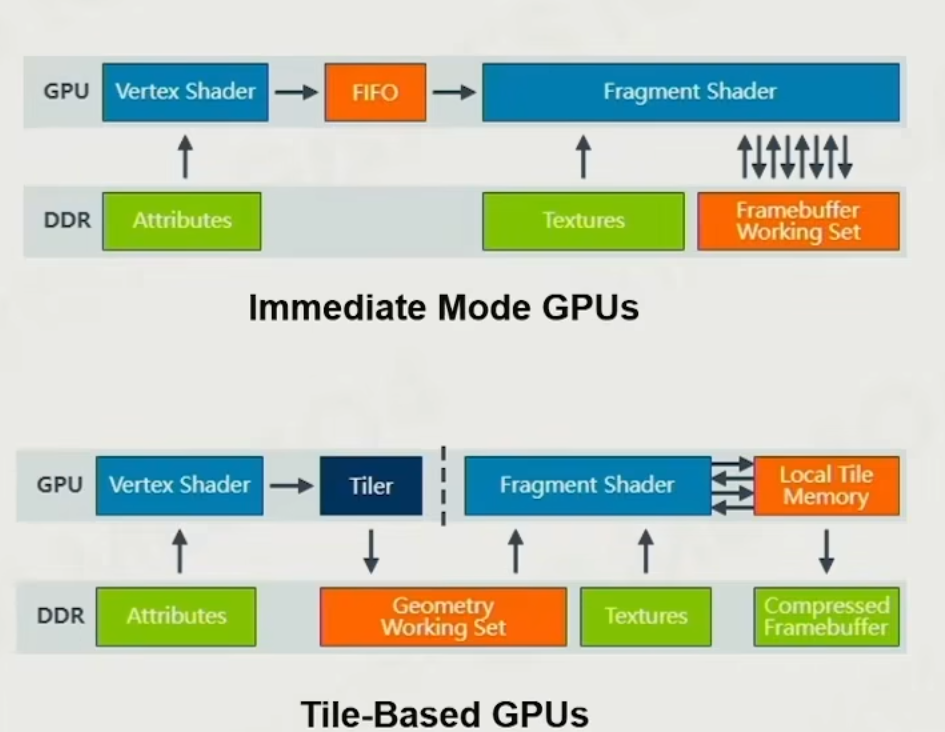
硬件pipeline
现代的系统硬件架构非常多样,PC、移动端、主机,且迭代速度很快,不深入了
下图是适用于移动端Tile-Based Rendering
如何渲染物体
MeshComponent(Renderable)
Mesh数据如何存储? 顶点、法线、uv,(需要节约内存)

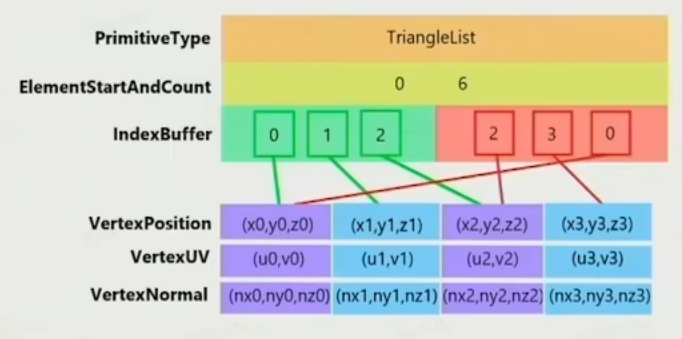
为什么每个顶点都要存储法线?因为在处理折线的时候可能会出现同一个点不同法线
材质系统(渲染材质)
冯模型
PBR
Subsurface
....
纹理
Albedo
Normal
roughness
...
Shader
投影变换
详见game101 MVP投影 + Transform
SubMesh
切割mesh为子mesh,有不同的贴图、材质和sheader

如何处理大量渲染资产?
通过一个ResourcePool,记录下引用
实例化GO
合批处理:进行材质排序与静态化技术,极大地减少GPU drawCall,
可见性裁剪
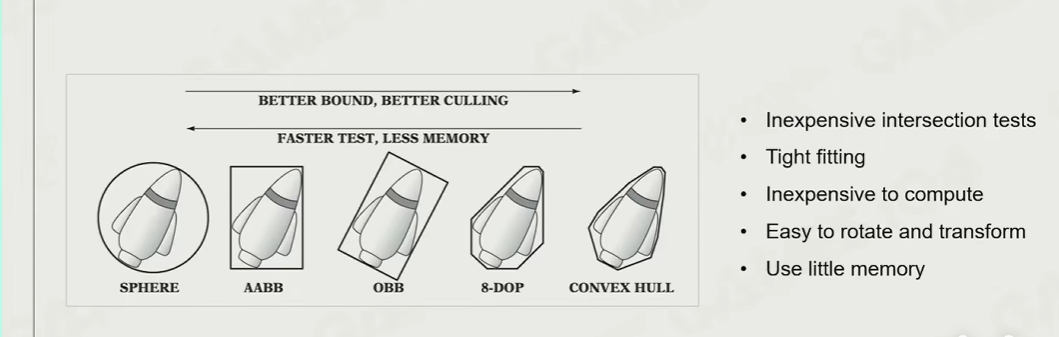
包围盒裁剪
判断物体的包围盒是否在视锥之外,裁剪掉相机之外的物体
常见的包围盒:AABB、OBB、convexHull
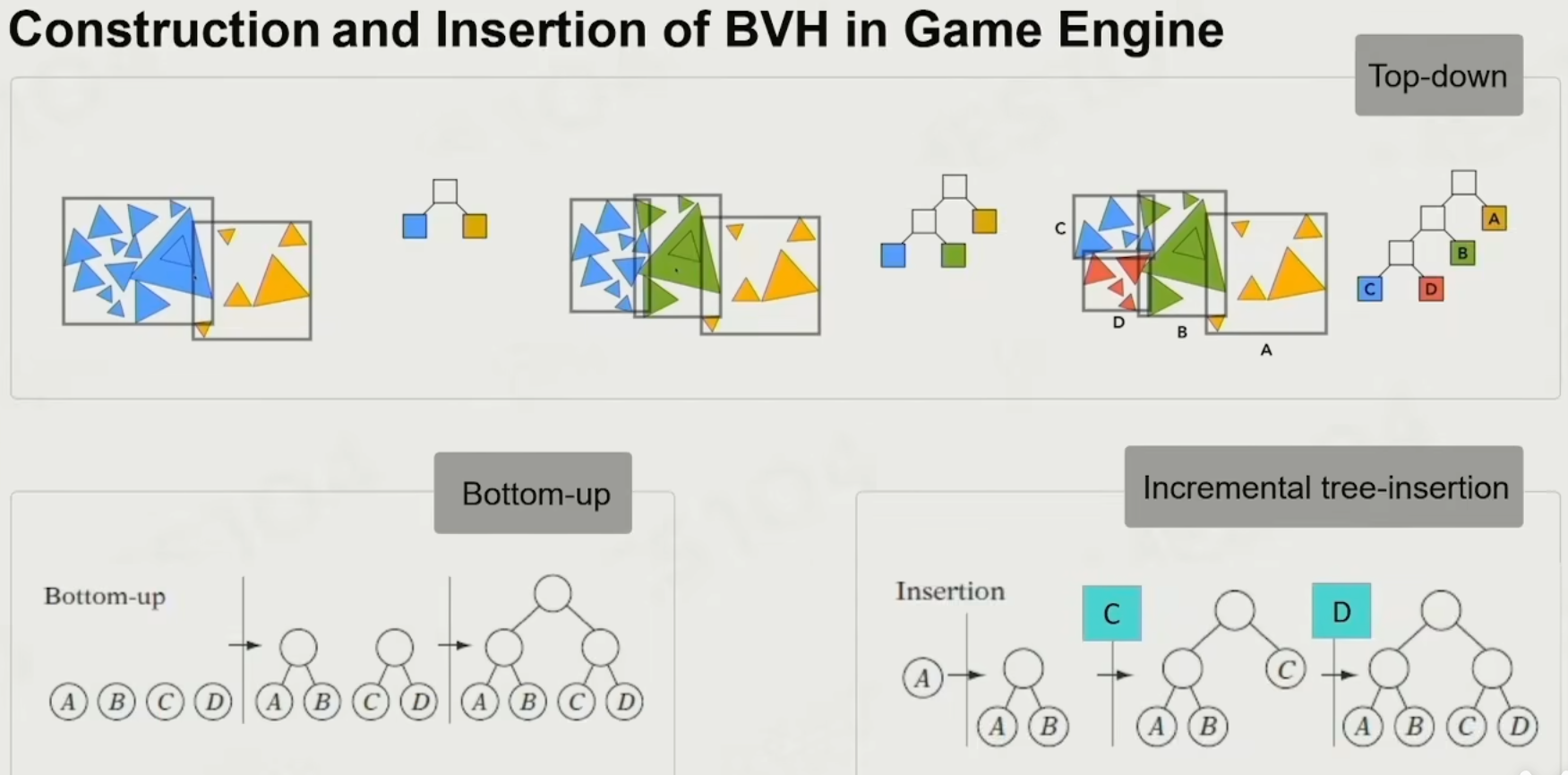
空间划分裁剪
比如四叉树和BVH,从上到下的节点依次判断
如图是BVH的culling划分
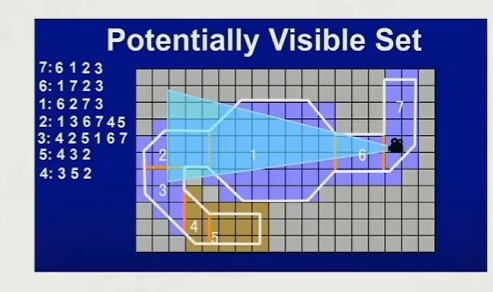
PVS算法:即通过空间划分,记录在某个区域内的其他区域,选择性的渲染,不仅仅是用来作为culling算法,也是一种管理加载资源的方式
GPU Culling
最常用的Culling方法,直接通过显卡的计算判断需要被剔除的物体、同时也会结合z-buffer
纹理压缩
不能使用JPG和png传统算法,因为这些算法在随机取点的时候效率很低
所以常用的算法是BlockBased,这是一种有损压缩算法,即将图片切割为一个个4*4像素的小块,记录下这个小色块中最亮和最暗的颜色,其他像素是两个颜色的插值
现代模型管线
Cluster-Based Mesh Pipeline
基于集群的网格渲染管线,代表技术是ue5的nanite,以及团结引擎的最新版
核心机制是 预处理将网格体拆分成分层集群,渲染时按需流送和显示,而且可以做到自适应的LOD,并且只有当前可见且需要的几何体数据才会被送入GPU内存,实现了几何体数据的细粒度流送

光照
双向反射渲染(BRDF)方程,该方程的前提是假设所有的光线都是可以线性相加的

radius:辐射度,即物体反射出的能量
inradius:入射的能量
真实的光线反射非常复杂,有非常多的挑战:
光的可见性:
阴影
光源本身的复杂度 : 点光源、面光源、直射光
如何实现快速的光源radius计算,包括采样与卷积计算
如何处理解决光线多次反射,与第二点是一个无限递归的东西
基础光照解决方法

ambientLight + simpleLight = result
Ambient light:环境光、可以使用环境贴图
Blinn-Phong模型材质
Ambient + diffuse(漫反射) + specular
但是此模型的问题是能量不守恒或者说是能量不保守,出射能量 > 入射能量。因为diffuse和specular是没通过光线计算出来的,而是直接使用幂计算,所以在使用此模型做光线追踪时,不断反射出的光线越来越多,导致室内光线变得很亮
阴影
shadowMap作为主流方法:即通过对光源的反向投影得到 z-buffer
详见game101
shadowMap的缺点:相机对物体的采样率和反向对光源投影的采样率是不一致的,导致出现很多自遮挡画面问题
基于预计算的全局光照
傅里叶变换
核心思想:任何复杂的、看似无规律的函数(或信号),都可以分解为一系列不同频率、不同振幅、不同相位的简单正弦波(或余弦波)的叠加。
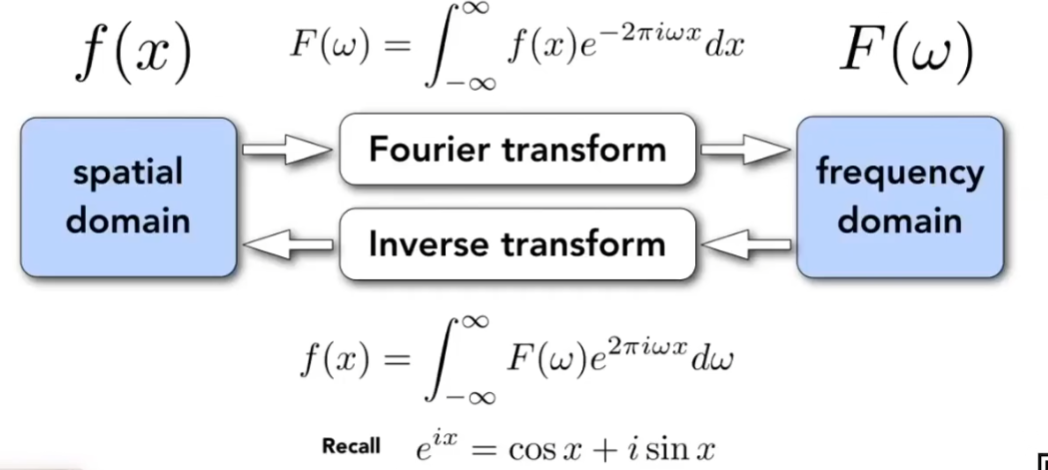
如图,从f(x)到F(x)其实就是变成一个傅里叶级数 ,这个原本的函数f(x)可以变成多个不同频率的F(x)相加
傅里叶级数展开方程(针对的是周期函数):
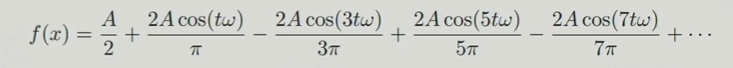
所以通过傅里叶变换可以将一张图片实现从空间域到频域的转变
详见game101
实际应用
球谐函数
与傅里叶变换的思想相似,不过是在一个极坐标下,对任何形状的拟合(比如初中课本中的电子云轨道就是用球谐函数拟合的)
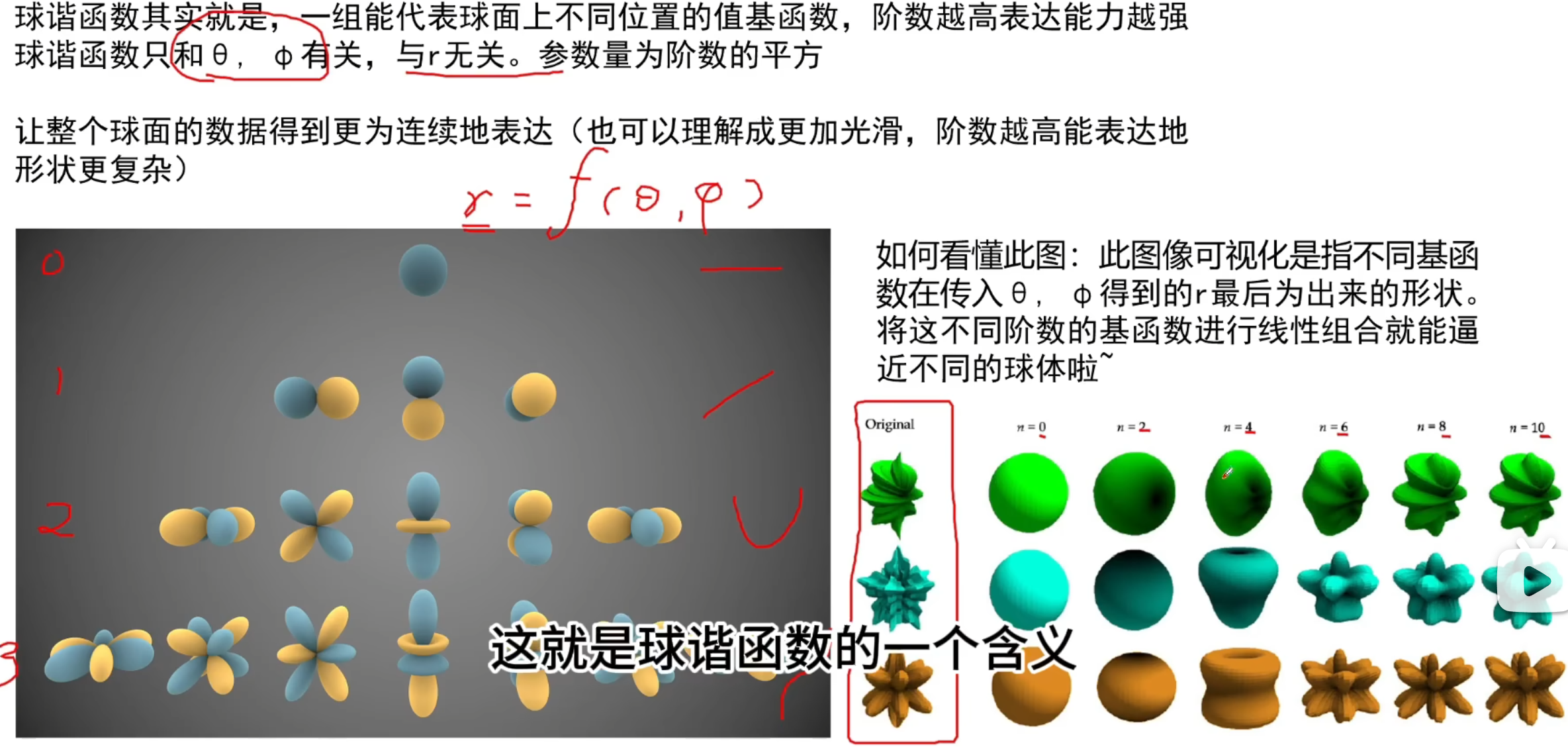
其基函数的二阶导永远是0,即它的变化永远是光滑的
实际应用
记录irradius

LightMap
即通过数学公式预计算出的光照,空间换时间
缺点是烘焙时间长,只能烘焙静态物体
光照探针(Light Probe)
在空间上放一堆光照探针,连接出很多的四面体,做光照插值
反射探针(Reflection Probe)
光照探针一般针对diffuse,只需要低频,所以可以做一些压缩算法,可以高密度低精度
但是反射需要对高频更敏感,需要高精度低密度
光照探针 + 反射探针可以同时处理静态和动态两种物体
PBR 基于物理的渲染
微平面理论
物体的粗糙度由表面的法线聚集度决定

由图可知: 球面漫反射 c/π + 高光反射 cookTorrance模型 = 反射光
c表示入射光能量
什么是DFG?
D : NormalDistributionFunction 法线分布方程 α表示粗糙度roughness,表示法相分布的随机度
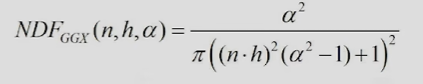
G:自遮挡光照,需要D作为参数
F:菲涅尔现象 当视线非常贴近物体表面切线时,反射系数急剧增加,需要一个fresnel参数
所以只需α和fresnel两个参数即可表达物体表面物理材质
主流的PBR模型
SpecularGlossiness(SG模型)
几乎没有参数,属性使用图来表达,可以精准地实现像素级控制,但是fresnel不好控制
三张图:
Diffuse:有RGB三个通道
Specular:也是RGB通道,控制fresnel参数,不同的RGB值有不同的菲涅尔值
glossiness:控制粗糙度
MetallicRoughness模型(MR模型)
其实是基于SG模型的封装
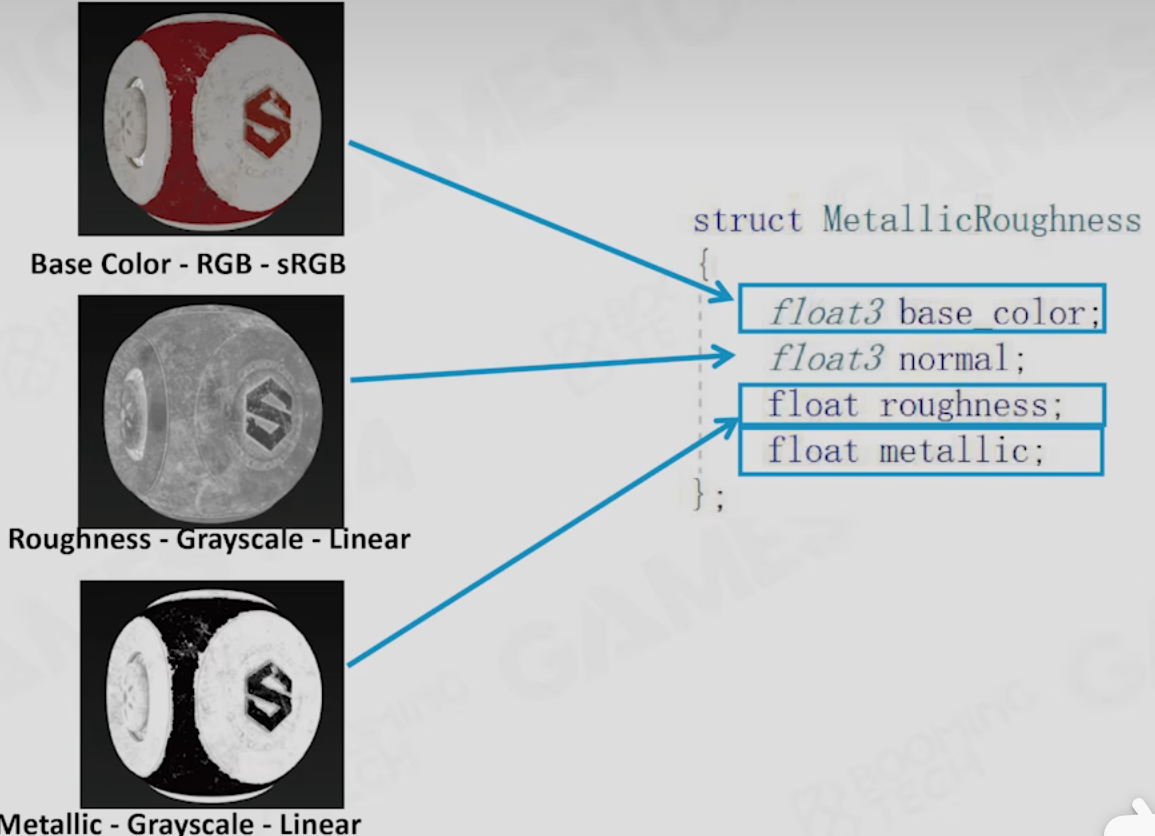
新增一个metallic值,当metallic值低时,颜色不进入Specular的fresnel反射项,
当metallic值高时,颜色会被大量抽走放到fresnel项
缺点是介于金属和非金属之间时会出现白边
Image-Based Lighting(IBL)
针对上述提到的BRDF的PBR模型,也可以预处理环境光照,得到的是一个近似解,这里不会着重推导,只给出最后公式:
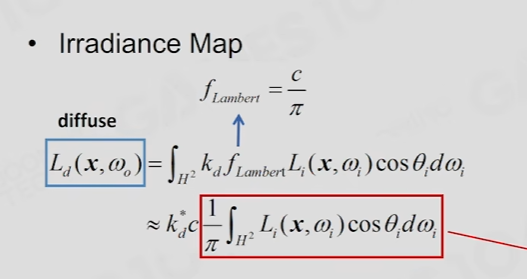
diffuse预计算
diffus可以提前计算,快速卷积,也属于空间换时间
Specular预计算
同理,Specular也可计算,通过将不同的粗糙度(即α)计算出来的结果存到了不同层级的mipmap里面,因为粗糙度越高,数据就越低频,所以可以将其存放到低层级的mipmap。其实类似于一张速算表。

IBL lookUpTable(LUT)
有两个维度,一个cosθ,决定diffuse,一个α,决定specular,
而剩下的一个fresnel项,则会变成一个线性的属性

所以最终的公式是:

Shadow
主流方法-Cascade Shadow
其实就是分层级的ShadowMap,近处的Map采样率高、密度高,远处的采样率低、密度也低
难点:在不同层级的Map之间需要做边界插值,避免阴影边缘形变
缺点:存储空间大、计算量大
软阴影:PCF、PCSS技术、variance
总结
5-10年前的3A渲染引擎:

全局光:LightMap + Lightprobe 技术
材质:PBR模型 + IBL技术
阴影:联级阴影 + VSSM软阴影
未来技术趋势
硬件快速发展,比如GPU发展带来的实时光追技术、实时全局光照
算法升级,3s材质等等
参与讨论
(Participate in the discussion)
参与讨论